
Leer in 8 minuten
- Wat de architectuur van een cloud dataplatform zo anders maakt
- Waarom ‘ontkoppelbaarheid’ essentieel is in zo’n architectuur
- Welke vijf stappen je moet zetten om een dataplatform werkelijkheid te maken
Waren veel bedrijven tot voor kort nog huiverig om hun data en BI-toepassingen te verhuizen naar de cloud, inmiddels is bijna iedere organisatie op de één of andere manier bezig met het implementeren van BI-oplossingen op een cloud platform. Platformen als Microsoft Azure en AWS bieden – op een zeer schaalbare manier – geavanceerde functionaliteit voor data-integratie en analytics. Toch worstelen veel bedrijven hoe ze binnen alle beschikbare mogelijkheden de juiste keuzes maken.
Kortgeleden schreef Alexander van Helm een interessant artikel over het moderne dataplatform, ‘designed for the cloud’. In dat artikel introduceert hij een flexibele referentiearchitectuur die handvatten biedt bij het ontwerpen van een cloud dataplatform. In dit artikel leg ik uit hoe je – aan de hand van deze referentiearchitectuur – in vijf stappen zo’n dataplatform werkelijkheid maakt.
Stap 1: de bouwtekening maken
De eerste stap in het realiseren van een dataplatform is het specifiek maken van de referentiearchitectuur voor je eigen situatie. Hierbij bepaal je welke lagen van de architectuur je (nu) nodig hebt en welke onderdelen van iedere laag voor jou van belang zijn. Daarnaast bepaal je hoe je de eisen van jouw bedrijf met betrekking tot beschikbaarheid, tijdigheid, autorisatie en data governance kunt realiseren. Een functionele analyse van de informatiebehoefte, zoals we dat traditioneel gewend zijn, is hier niet de juiste aanvliegroute. Die behoefte is een momentopname en verandert sneller dan we oplossingen kunnen implementeren. Misschien is er bijvoorbeeld op dit moment geen enkele behoefte om data te ontsluiten via een app, maar wordt die vraag op korte termijn wel relevant door ontwikkelingen in de markt waarin je opereert.
Om die reden is ‘ontkoppelbaar’ het kernwoord voor de architectuur van je nieuwe dataplatform. Iedere component moet, op ieder moment, eenvoudig vervangen kunnen worden door een component die past bij de informatiebehoefte en requirements van dat moment. Die ontkoppelbaarheid gaat verder dan het kunnen vervangen van een informatieproduct of een stuk dataverwerking. De architectuur moet zo ontworpen zijn dat je in de toekomst ook een volledige storage-component kan vervangen of zelfs in staat bent om te switchen naar een ander cloud-platform.
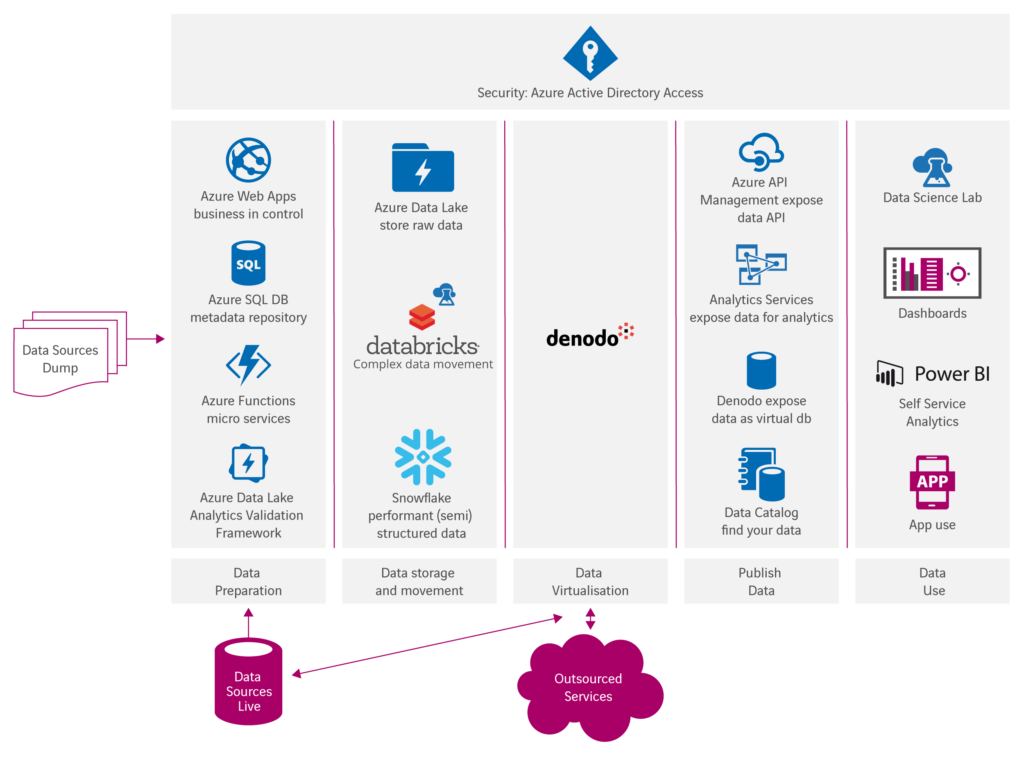
Hoe bereik je die ontkoppelbaarheid? Door zoveel mogelijk te automatiseren, genereren en virtualiseren! Een voorbeeld hoe het dus niet moet, is de ETL-component in een traditioneel data warehouse. In de meeste gevallen kost het enorm veel inspanning en tijd om ETL-processen aan te passen bij het switchen van platform of database. Behalve als de ETL-processen met een ‘generator’ zijn gemaakt en snel opnieuw gegenereerd kunnen worden voor de nieuwe situatie. Stel nu dat je oorspronkelijk gekozen hebt voor Azure SQL DWH voor je dataplatform en je wil vanwege performance en schaalbaarheid overstappen naar een cloud database als Snowflake. Dan wil je niet tientallen scripts moeten herschrijven. De nadruk bij het ontwerpen van je cloud data-architectuur ligt dus niet op wat ieder component doet, maar hoe je dat component zo makkelijk mogelijk kunt vervangen.
Gebruik van datavirtualisatie is naar mijn idee de meest extreme vorm van ontkoppeling. De inzet van een datavirtualisatieplatform zorgt er voor dat grote onderdelen van je architectuur virtueel worden opgebouwd en niet fysiek en dat replicatie van data tot een minimum beperkt wordt. Aanpassingen in virtuele componenten zijn veel sneller te maken dan in fysieke objecten.
Stap 2: de route plannen
Als de bouwtekening er ligt, kun je gaan nadenken in welke stappen je het dataplatform gaat realiseren. Begin je met het migreren van bestaande toepassingen of juist op veel gewenste nieuwe functionaliteiten? Het lijkt logisch om bij die eerste vraag te beginnen, maar vaak is dat niet de beste keuze. Want wat is in dat geval de business case? Je levert iets op dat er al was. Met het ‘aanzetten’ van een nieuwe data-toepassing creëer je echter meteen meerwaarde voor je gebruikers. Die meerwaarde vergroot bovendien het draagvlak voor de verdere ontwikkeling van het platform. Het wordt natuurlijk anders als er veel te verbeteren valt in je huidige toepassingen. Als die niet goed werken, veel fouten of hiaten bevatten of te langzaam zijn. In dat geval kun je juist veel enthousiasme verwachten als je een verbeterde cloud-variant oplevert.
Anders dan bij het uitdenken van de architectuur, is functionaliteit bij het bepalen van de route die je neemt juist wel leidend. De referentiearchitectuur stelt geen eisen aan de volgorde waarin architectuurlagen of -objecten geïmplementeerd worden. Daarin zie je direct de flexibiliteit van de cloud terug. Het is dus vooral een kwestie welke toepassingen jouw organisatie het meeste gaan opleveren. Uiteraard is het wel belangrijk om slim naar onderliggende data te kijken. Data die nodig is voor een toepassing zal uiteindelijk – op enig moment – op het cloud-platform aanwezig moeten zijn. Het kan dus geen kwaad om snel (en in de juiste volgorde) te beginnen met het migreren en integreren van data in de cloud.
Ben je van plan een bestaande omgeving (data warehouse, data lake, data mart etc.) te migreren naar de cloud? Dan is de volgorde van implementatie wel degelijk van belang! Het voert te ver om dat hier te bespreken, maar we gaan daar in een volgend artikel uitgebreid op in.
Stap 3: de bouwstenen kiezen
Als je componenten van je dataplatform zo makkelijk kunt vervangen, is het dan wel zo belangrijk om goede keuzes te maken? Uiteraard wel. Vervangen kan misschien makkelijk, maar het kost nog steeds tijd en geld. Bovendien wil je wel dat geïmplementeerde componenten ook doen waar ze voor bedacht zijn. Voor veel bedrijven zit de uitdaging er vooral in om überhaupt keuzes te maken, omdat veel IT’ers – hoe raar het misschien ook klinkt – toch de neiging hebben om vast te houden aan wat ze kennen. “We werken al jaren met database XYZ, de medewerkers hebben daar kennis van, dus laten we daar mee doorgaan.” Dat is misschien wel de grootste valkuil bij het migreren naar een modern, flexibel en schaalbaar dataplatform in de cloud: vasthouden aan oude principes. Als je aan de slag gaat met nieuwe technologieën voor data-integratie zal je zien dat ontwikkelaars die enorm snel oppakken. Ik noem het zelf graag ‘knoppenkennis’: als je snapt hoe data-integratie werkt, is een nieuwe tool snel genoeg geleerd. Aan de ‘output-kant’ – bij de gebruiker van de informatie – ligt dat anders. Daar tref je meer mensen die minder snel wennen aan een nieuwe tool of een nieuwe inrichting van een bestaande tool. Om die reden moeten de componenten daar met extra zorgvuldigheid gekozen worden.
Wat is de rol van de data-architect bij het kiezen van de juiste bouwstenen? Die bewaakt de samenhang en ontkoppelbaarheid. Bovendien checkt hij of keuzes voldoen aan de architectuur requirements (beschikbaarheid, tijdigheid, autorisatie, data governance etc.). Dat betekent dus, anders dan vroeger, veel meer betrokkenheid van de architect bij het implementeren van het dataplatform. Waar we traditioneel met vaste componenten (ETL, database en BI-tools) werkten, met vooraf omschreven ontwerp- en implementatieregels, worden er nu immers met grote regelmaat nieuwe componenten aangeschakeld.
Stap 4: testen voor gebruik
Bij de ontwikkeling van een modern cloud dataplatform gaat het dus vaak meer om het testen van keuzes dan om de keuze zelf, aangezien je zo makkelijk onderdelen van het platform kan ‘aanzetten’ en uitproberen. Al is het natuurlijk wel zaak om goed af te bakenen wat je wel en niet uitprobeert, zodat je niet alleen maar test en nooit implementeert. Haal er daarom ervaren mensen bij die goede adviezen kunnen geven op basis van praktijkervaringen. Die adviezen probeer je vervolgens uit. We hebben het dan vaak over een proof of concept, maar dat is eigenlijk een verkeerde benaming. Een PoC klinkt te veel als een test waarvan je de resultaten weer weggooit. Terwijl je juist zo moet testen dat je de resultaten – bij een geslaagde test – ook meteen in gebruik kunt nemen. Veel meer een vorm van prototyping dus.
Het mooie is dat je dit in een cloud omgeving ook gewoon met grote complexe componenten kunt doen. Geen grote onderzoeken vooraf, maar gewoon direct uittesten in je eigen omgeving. Wil je datapipes inzetten? Of een app real time aansluiten op je platform? Je activeert de functionaliteit, probeert het uit en als het werkt, ontwikkel je het meteen door tot een productiewaardige oplossing. Bijna alle cloud functionaliteiten zijn schaalbaar van kleine implementaties tot bedrijfsbrede oplossingen. Grote, krachtige toepassingen – zoals bijvoorbeeld Azure data factory in combinatie met een Snowflake MPP-database – komen daarmee binnen bereik van iedere organisatie.
Stap 5: bouwen in kleine stappen
En dan kun je aan de slag. De architectuur is uitgedacht, je weet in welke volgorde je gaat werken en met welke bouwstenen, en dan? Anders dan je gewend bent in je oude data warehouse omgeving, kun je nu wel snel en in kleine stappen aan de slag. Je nieuwe cloud-architectuur leent zich uitermate goed om iteratief te ontwikkelen. Wat je vroeger een jaar kostte, kun je nu in één tot twee maanden opleveren, waarbij je de gebruiker ook nog eens aan de hand meeneemt met behulp van prototyping. Misschien begin je wel met een subset van je data en ontsluit je die data bij het eerste prototype totaal anders dan in de uiteindelijke situatie. Je begint bijvoorbeeld met fysieke data marts en vervangt die pas later door virtuele tabellen. Met alle mogelijkheden van het cloud platform kan je snel van links naar rechts door de architectuur heen werken en in iedere sprint een werkend product opleveren. Zo kun je eindelijk echt agile-BI toepassen!
Maar hoe zit het dan met je bestaande data warehouse en BI-toepassingen? Die zijn niet voor niets ontwikkeld. Waarschijnlijk wil je de functionaliteit ervan (gedeeltelijk) overbrengen naar je nieuwe dataplatform. Er is helaas geen ideale standaardmanier voor die migratie. Alles 1-op-1 migreren is in ieder geval nooit een goede werkwijze. De beste aanpak voor jouw situatie hangt af van allerlei factoren. In een volgend artikel geven we belangrijke tips voor de beste volgorde en aanpak van die migratie. Ondertussen staat niets je in de weg om met nieuwe toepassingen de eerste stappen te zetten op weg naar een flexibel dataplatform in de cloud!
Wat levert het jouw organisatie op als nieuwe data-toepassingen veel sneller opgeleverd kunnen worden?