
Leer in 9 minuten
- Waarom datakwaliteit een belangrijke, maar complexe uitdaging is
- Hoe je datakwaliteit kunt meten op zes aspecten
- Hoe je van kwaliteitsverbetering een continu proces maakt
Het grootste struikelblok van data gerelateerde projecten is een probleem waar gek genoeg maar weinig over gepubliceerd wordt: datakwaliteit. Een zoekopdracht naar ‘data warehouse’ levert ruim 6.000 maal zoveel resultaten op als wanneer je naar ‘datakwaliteit’ zoekt. Terwijl datakwaliteit al jaren de achilleshiel van veel business intelligence, analytics en data science projecten is. Als data beschikbaar komt voor gebruik, wordt immers meteen duidelijk wat er mis is met die data. Een probleem dat al snel bij de eigenaren van de data of de data-architectuur terug wordt gelegd, maar die kunnen het zonder goede samenwerking met de datagebruikers niet zomaar oplossen. Als überhaupt al duidelijk is welke kwaliteit er door wie verwacht wordt. Er is daarom een andere benadering nodig van datakwaliteit, geïntegreerd in het data governance beleid van je organisatie!
Voorbeelden
Laat ik beginnen met een paar voorbeelden om de complexiteit en diversiteit van het begrip datakwaliteit duidelijk te maken:
Uit mijn eigen verleden herinner ik me nog goed dat er een audit werd uitgevoerd op een data warehouse waar ik aan werkte bij een verzekeringsbedrijf. Dit data warehouse werd zowel door marketing & verkoop als door het actuariaat gebruikt. De marketeers wilden graag opgeschoonde data kunnen analyseren, de actuarissen wilden juist ook de onvolkomenheden in de data zien. De voorgestelde oplossing was om met error buckets te gaan werken, waar ik het niet mee eens was. Naar mijn mening moest het data warehouse juist meerdere ‘waarheden’ kunnen tonen, zodat duidelijk werd welke verbeteringen nodig waren en hoe de voortgang van verbeteringen verliep.
Een ander goed voorbeeld komt uit een project waarin de toentertijd nieuwe International Financial Reporting Standards (IFRS) werden geïmplementeerd bij een multinational. Tijdens de implementatie bleek dat bepaalde boekingen niet goed opgenomen werden in de geconsolideerde jaarrekening. Met als gevolg een verschil in de kosten van enkele miljoenen. Een fout die tot dan toe niet opgevallen was vanwege de significantie van dit bedrag ten opzichte van de totale kosten.
Tot slot een voorbeeld dat laat zien waarom samenwerking tussen afdelingen zo belangrijk is op het gebied van datakwaliteit. De IT-afdeling van een groot retailbedrijf wil graag meer data ter beschikking stellen aan afdelingen voor self service gebruik. Tijdens de eerste pilot projecten blijkt echter dat er veel issues zijn rondom de correctheid en compleetheid van de data. Om die reden wil de IT-afdeling geen nieuwe projecten starten tot de kwaliteit van de data op orde is. Maar zonder gebruik van de data door de business afdelingen, zal nooit goed duidelijk worden waar het aan schort met de datakwaliteit. Een vicieuze cirkel die alleen doorbroken wordt als gebruik van de data en verbetering van de kwaliteit van die data hand in hand gaan.
Uit deze voorbeelden wordt duidelijk dat er eigenlijk altijd issues met datakwaliteit zijn en datakwaliteit geen kwestie is van ‘alleen maar juiste data aanbieden’. Om datakwaliteit goed aan te pakken is het juist essentieel dat je data-architectuur in staat is zowel ongeschoonde als geschoonde gegevens aan te bieden, en capabilities bevat om datakwaliteit te meten, monitoren en tonen.
Datakwaliteit, hoe leg je dat vast?
Bij het definiëren van een use case voor je data-architectuur, zou de verwachte datakwaliteit – én de manier waarop je die kwaliteit gaat meten en verbeteren – altijd onderdeel moeten zijn van de user story. Zo weten gebruikers vooraf niet alleen wat ze kunnen verwachten, maar ook wat en hoe er verbeterd gaat worden in de toekomst. Dat helpt bij de acceptatie en zorgt voor vertrouwen, zodat je samen aan verbetering van de kwaliteit kunt werken. Belangrijk, want ook hier geldt: vertrouwen komt te voet en gaat te paard!
Maar hoe leg je de datakwaliteit vast? Ken je de data al goed genoeg om wat over de kwaliteit te zeggen? Of leg je verwachtingen neer en kijk je of je die verwachtingen waar kunnen maken? Een leuk, verwachtingen, maar op welke aspecten moet ik dan letten?
Zoals met alles rondom data governance gaat het om ‘vastleggen’, zodat je weet waar je aan toe bent. Dat vastleggen doe je in het geval van datakwaliteit op zes aspecten (zie de figuur hieronder). Daarbij leg je alleen die aspecten vast die op dit moment voor de betreffende dataset van belang zijn. Je wilt je immers niet laten belemmeren in het gebruik, aangezien juist dat gebruik je gaat helpen de andere aspecten in te vullen. Zo werk je toe naar een eerste product (minimal viable product) dat je daarna altijd nog verder kan laten groeien. Het is vooral van belang dat je de mogelijke kwaliteitsverbeteringen niet uit het oog verliest. Ga de datakwaliteit dus ook op deze zes aspecten monitoren en beleg de verbeteringen in je data governance beleid, via de reguliere overlegstructuur, maar daarover later meer. Laten we eerst nog wat verder in de details van deze zes aspecten van datakwaliteit duiken.
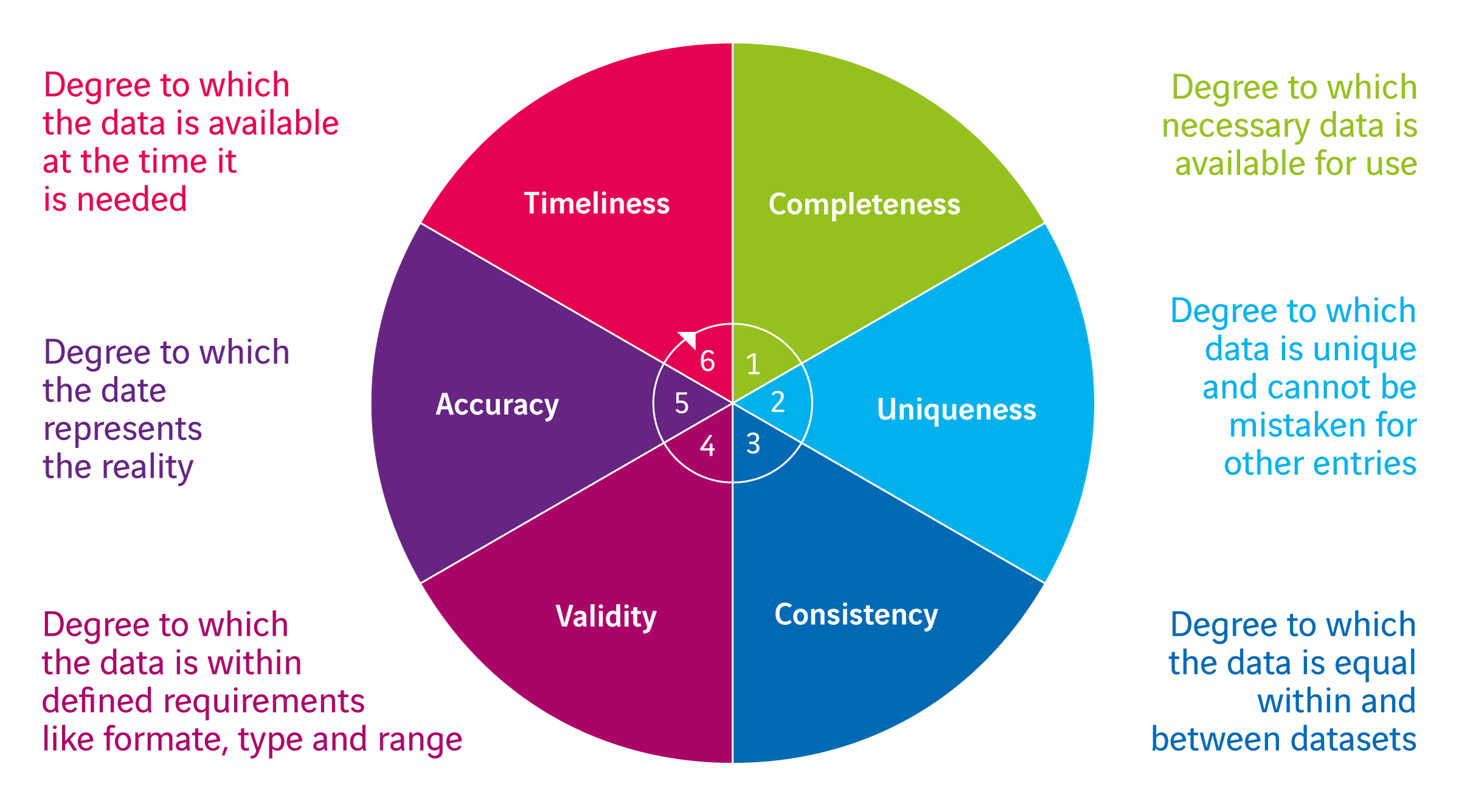
- Timeliness
Hoe oud mag de data zijn om de gebruikersvraag goed te kunnen ondersteunen en is dat haalbaar? Vroeger werd vooral gedacht dat datastromen er alleen zijn om tactische en strategische beslissingen te ondersteunen en dat data daarom vrij ‘oud’ mag zijn (een maand, week of dag oud). Tegenwoordig zie je juist de tegenovergestelde gedachte, dat bijna elke datastroom real time moet zijn. Probeer gewoon vast te stellen wat er écht nodig is en monitor de werkelijke verversingsmomenten goed. - Completeness
Is de geleverde dataset volledig of mist er nog bepaalde data, bijvoorbeeld omdat die uit een ander systeem moet komen? Denkende vanuit het bedrijfsproces: welke data heb ik nodig en heb ik die ook? Leg daarbij de definities van de gewenste data goed vast en onderzoek in hoeverre je over alle data beschikt, volgens die definitie. Dit hoeft niet altijd over compleetheid in attributen te gaan. Denk bijvoorbeeld ook aan ‘standen’ uit een bronsysteem om momentopnames te kunnen vergelijken voor een financiële vierkantstelling. - Uniqueness
Is dit echt de goede versie of weergave van de gewenste data? Of zijn er mogelijke duplicaten? Denk bijvoorbeeld aan meerdere registraties van gegevens van dezelfde klant. Dit heeft natuurlijk een directe relatie met hoe het master data management is ingericht. Wat is de waarschijnlijkheid dat iets een duplicaat is? - Consistency
Hoe consistent is de dataset? Kloppen de referenties? Kloppen de hiërarchieën in de data? Spreekt de data zichzelf niet tegen? En blijft de data consistent als je die verwerkt? Denk hierbij ook aan complexere zaken, bijvoorbeeld of een ouder niet jonger is dan zijn kinderen. - Validity
Klopt het formaat van de data en vallen de waardes binnen de verwachting? Is bijvoorbeeld de spreiding van geboortedata wel juist, of is bijna iedereen jarig op 1 januari? Ook bij dit aspect begint het bij eenvoudige controles (is een waarde wel numeriek), maar kan het doorlopen in de controle op complexe business rules waaraan voldaan moet worden. - Accuracy
Dit aspect is misschien wel het moeilijkst meetbaar: klópt de eigenlijke data ook echt? Is er data beschikbaar waarmee dit gecontroleerd kan worden? Dit aspect hangt sterk samen met consistency en completeness.
Als we terug gaan naar de voorbeelden aan het begin van dit artikel, zie je meteen het belang van de onderverdeling in (en de samenhang van) verschillende aspecten van datakwaliteit. ‘Error buckets’ verhogen weliswaar de consistency, maar verlagen de completeness. Bij de IFRS implementatie bleek dat zowel consistency als completeness niet aangetoond waren. En in het laatste voorbeeld werd er alleen gesproken over juist of niet juist, zodat een genuanceerde discussie over datakwaliteit onmogelijk was.
Van vastleggen naar verbetering
Voor veel bedrijven is het vastleggen van datakwaliteit al een grote stap voorwaarts. Maar met alleen vastleggen zijn we er nog niet. Vastleggen moet wel gaan leiden tot acties voor continue verbetering van de datakwaliteit. Om dat te bereiken moet kwaliteitsmonitoring van data een vast agendapunt worden van de reguliere data governance overleggen. Zodat je samen kunt vaststellen hoe en waar de kwaliteit verbeterd is en waar juist meer aandacht nodig is. Om dat te kunnen, heb je wel een flexibele data-architectuur nodig die alle geschoonde én ongeschoonde data bevat en beschikt over capabilities om datakwaliteit te monitoren en aan te tonen waar de problemen zitten. Waarmee je dus ook daadwerkelijk kunt meten of die datakwaliteitsproblemen inderdaad minder worden.
Mijn overtuiging is dat datakwaliteit een van de belangrijkste onderdelen van data governance is en daarmee ook geïntegreerd onderdeel moet uitmaken van een moderne data-architectuur. Gelukkig zien leveranciers van data governance software dat ook steeds meer. Een mooi voorbeeld daarvan is de recente overname van OwlDQ, marktleider op het gebied van predicitive data quality software, door Collibra, leverancier van data governance oplossingen.
Samengevat
Datakwaliteit is een te complex onderwerp om te benaderen vanuit een ‘alleen maar juiste data aanbieden’ aanpak. Het is een multidimensionaal vraagstuk dat vanuit verschillende aspecten benaderd moet worden. Zorg allereerst dat datakwaliteit überhaupt gemeten wordt in je organisatie en ontwikkel capabilities in je data-architectuur om datakwaliteit te monitoren. Maak het opstellen van verbeteracties en het monitoren van verbeteringen onderdeel van je reguliere data governance overleggen. Zodat kwaliteitsverbetering een continu en meetbaar proces wordt!
Is meten en monitoren van datakwaliteit al een capability binnen jouw data architectuur?
